

Products and services


My previous blog summarised the orthodox argument why adverse selection in insurance is a bad thing. This present blog gives the counter-argument from my book Loss Coverage: Why Insurance Works Better with Some Adverse Selection.
In essence, the counter-argument relies only on simple arithmetic, and can be illustrated by a toy example.
Think of a life insurance market, and suppose the population consists of just ten people, with two alternative scenarios for life insurance risk classification. First, risk-differentiated prices are charged, and a sub-set of the population buys insurance. Second, risk classification is banned, leading to adverse selection: a different (smaller) sub-set of the population buys insurance. Assume that all losses and insurance cover are for unit amounts (this simplifies the argument, but it is not necessary).
The two scenarios are shown in the upper and lower parts of the illustration. The ‘H’ are high risks (probability of loss 0.04) and the ‘L’ are low risks (probability of loss 0.01). In each scenario, the shaded ‘cover’ above some of the ‘H’ and ‘L’ denote risks covered by insurance.
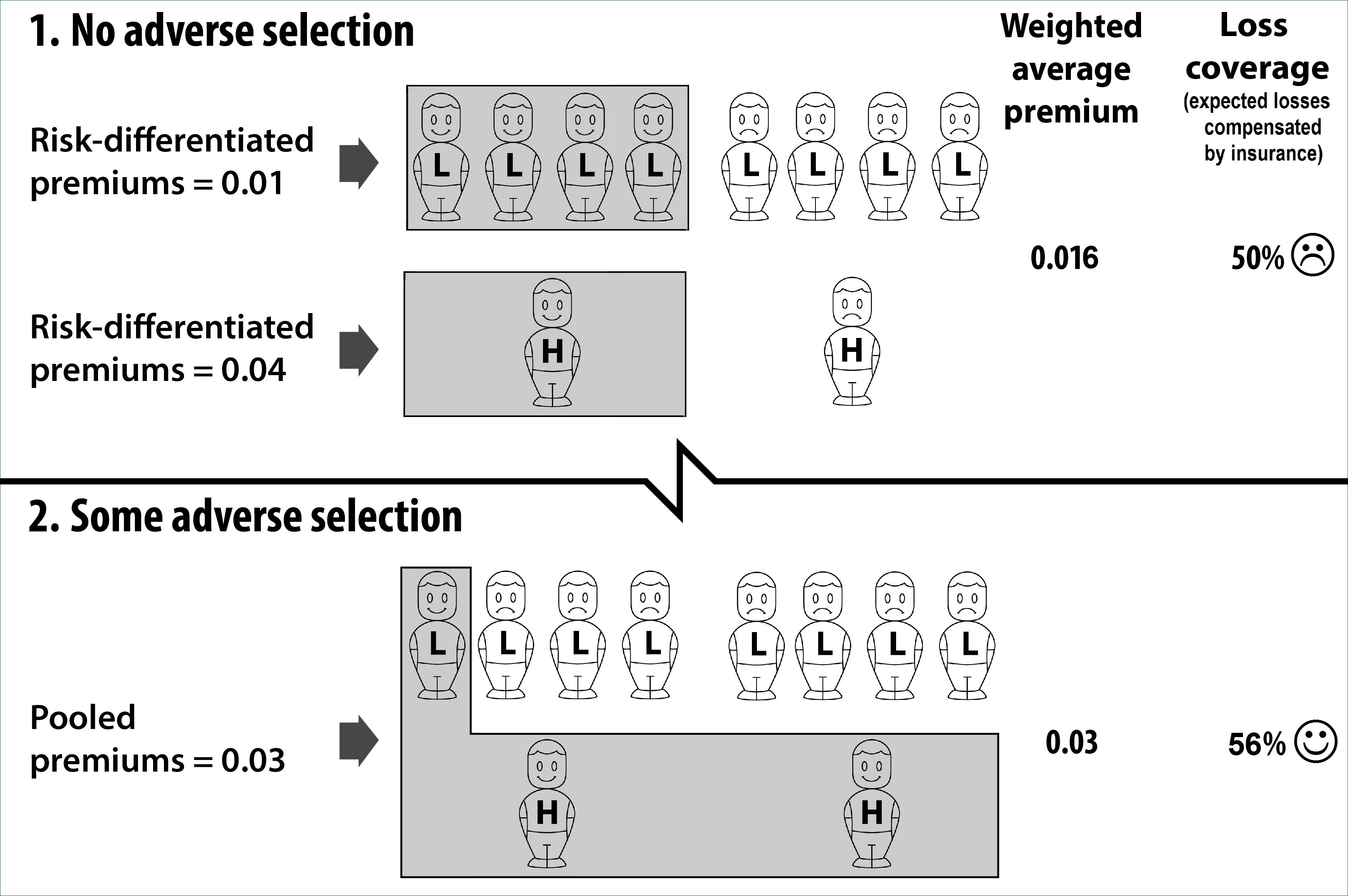
In Scenario 1, risk-differentiated premiums (actuarially fair premiums) are charged. The demand response of each risk-group to an actuarially fair price is the same: exactly half the members of each risk-group buy insurance. The shading shows that a total of five risks are covered. .
The weighted average of the premiums paid in Scenario 1 is (4 x 0.01 +1 x 0.04)/5 = 0.016. Since higher and lower risks are insured in the same proportions as they exist in the population, there is no adverse selection. The expected losses compensated by insurance for the whole population, which I call the ‘loss coverage’, can be indexed by (4 x 0.01 + 1x 0.04) / (8 x 0.01 + 2 x 0.04) = 0.50.
In Scenario 2, risk classification is banned, and so insurers have to charge a common ‘pooled’ premium to both higher and lower risks. Higher risks buy more insurance, and lower risks buy less. The shading shows that three risks (compared with five previously) are now covered. The pooled premium is set as the weighted average of the true risks, so that expected profits on low risks exactly offset expected losses on high risks. This weighted average premium is (1 x 0.01 +2 x 0.04)/3 = 0.03.
Note that the weighted average premium is higher in Scenario 2, and the number of risks insured is lower. These are the essential features of adverse selection, which Scenario 2 accurately and completely represents. But there is a surprise: with the adverse selection in Scenario 2, the expected losses compensated by insurance for the whole population are now higher. The loss coverage in Scenario 2 can be indexed by (1 x 0.01 + 2 x 0.04) / (8x 0.01 + 2 x 0.04) = 0.56.
I argue that Scenario 2, with a higher expected fraction of the population’s losses compensated by insurance, is superior from a social viewpoint to Scenario 1. The superiority of Scenario 2 arises not despite adverse selection, but because of adverse selection.
Some astute readers may have noticed that if the adverse selection progresses beyond Scenario 2 to its logical extreme, so that only a single higher risk remains insured, then loss coverage will be lower than with no adverse selection. This point is considered further in the book. For now, I merely reiterate that my message is one of moderation: I say that insurance works better with some adverse selection, not with any amount of adverse selection.

Guy Thomas is an actuary and investor, and an honorary lecturer at the University of Kent, Canterbury. His academic publications have received prizes from the Institute and Faculty...
View profile >Keep up with the latest from Cambridge University Press on our social media accounts.







Latest Comments
Have your say!