

Products and services


How do we know that global temperatures are rising? Why is Pluto no longer considered to be a full-sized planet? Are modal verbs such as must, shall and may are on the decline in the English language? These are examples of some of the questions across different disciplines to which we need to provide systematic answers. Over centuries, scholars have collected evidence about natural and social phenomena and observed patterns in that data. This gave rise to science and social science. The development of powerful computational technology in recent decades gave rise to data intensive approaches to such questions. One such approach is corpus linguistics, a discipline that explores large amounts of naturally occurring language data, known as corpora. Nowadays, computers can process corpora of a scale not possible before: millions and billions of words in a matter of few seconds. We can thus answer questions about language and society with reference to an unprecedented amount of evidence. But how do we interpret this evidence? Can we be sure that the patterns we see on our computer screens reflect reality? What if we are wrong?
Fundamental Principles of Corpus Linguistics takes a step back and looks for the theoretical foundations of corpus linguistics in particular and (social) science in general. The exploration is guided by the work of Karl Popper as well as other philosophers of science and theoreticians. We propose 48 Principles, on which, we believe, the discipline rests. In a nutshell, the monograph outlines an approach, which is conscious of the provisional nature of our understanding of language and society – we acknowledge the fact that we may be wrong (so called critical rationalism) – and critically builds on systematic observation through replication and falsification.
To return to an example at the beginning of this blog, in Chapter 7 of the book we explore the question ‘Are modal verbs such as must, shall and may are in decline in the English language?’ To answer the question we may look at corpora that sample the language at two points in time, say 1994 and 2014, and compare the frequencies of modal verbs. But what if the observation is a fluke? With corpus evidence, we can return back in time, say to the beginning of the 20th century, and take our measurements there. We will see a consistent pattern of decline of modal verbs as shown in Figure 1.
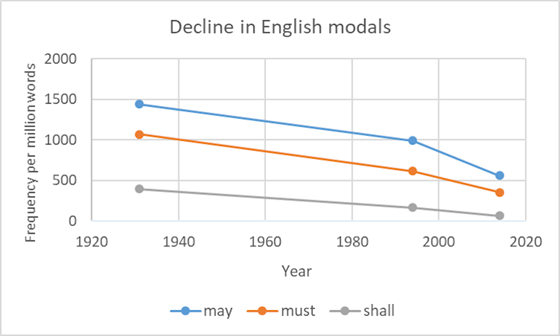
So can we now be certain that modals in English are used with a decreasing frequency over time? We have some strong corroboration in Figure 1, which is an important stepping stone for building our knowledge about the English language, but we can never be 100% certain – we need to be mindful, for example, that we are sampling three points in a very long span of time. Also, we need to be mindful of the principle metaphorically displayed on the cover of the book: no amount of observations of white swans can allow the inference that all swans are white but the observation of a single black swan is sufficient to refute that conclusion.
We can, of course, subject our hypothesis to further testing, as we do in Chapter 7, by looking at other available datasets, always being open to falsification – the possibility that we may be wrong. This, on a small scale, is a process through which (social) science and corpus linguistics moves forward on a large scale providing knowledge about language and society. The volume also discusses in detail the specific nature of observations in social science and the digital humanities given the dynamic character of the subject matter: societies and languages are extremely varied and change over time. This, in turn, makes our investigations more challenging but also, arguably, even more exciting and worth pursuing.


Tony McEnery is Distinguished Professor of Linguistics and English Language, Lancaster University and Changjiang Chair, Xi'an Jiaotong University. He has worked since the late 1980...
View profile >
Vaclav Brezina is a Professor at the Department of Linguistics and English Language and a member of the ESRC Centre for Corpus Approaches to Social Science, Lancaster University. H...
View profile >Keep up with the latest from Cambridge University Press on our social media accounts.







Latest Comments
Have your say!